Implementing Handwritten Digits Classification from Scratch with Python
ဒီနေ့ အားလုံးကိုပြောပြပေးသွားမှာကတော့ လက်ရေးကိန်းဂဏန်းတွေကို Multilayer Neural Network(MLP) အသုံးပြုပြီး Classification လုပ်နည်းပဲဖြစ်ပါတယ်။
Handwritten digits classification ဆိုရင်တော့ လူသိလည်းများသလို Neural Network ကို အခုမှစလေ့လာမယ့်သူတွေအတွက်လည်း အဆင်ပြေမှာဖြစ်ပါတယ်။ အခုပြောပြမယ့်နည်းလမ်းကတော့ Framework တစ်ခုမှမသုံးဘဲ Python code နဲ့ပဲအစအဆုံးရေးသွားမှာမို့ ပိုပြီးစိတ်ဝင်စားဖို့ကောင်းတယ်ပါတယ်။ TensorFlow, Pytorch, Caffe စတဲ့ Framework တွေနဲ့ မရင်းနှီးတဲ့သူတွေလည်း လိုက်လုပ်နိုင်သလို ရင်းနှီးတဲ့သူတွေကလည်း Framework အားမကိုးဘဲ လိုက်လုပ်နိုင်တာကြောင့် အားလုံးအတွက် အကျိုးရှိမယ်လို့ထင်ပါတယ်။
💫 Full Code
Step1 — Dataset and Downloading
ပထမဆုံးအနေနဲ့ data obtaining and preparing ကိုစလုပ်ပါမယ်။ ယူသုံးမယ့် dataset ကတော့ အားလုံးသိတဲ့ နာမည်ကြီး Mixed National Institute of Standards and Technology (MNIST) ပါ။ Machine learning algorithms တွေရဲ့ popular benchmark လို့လည်းပြောလို့ရပါတယ်။

Training data နဲ့ test data အရင် download လုပ်ကြပါမယ်။ MNIST ရဲ့ training dataset မှာ 60,000 training digits နဲ့ testing dataset မှာတော့ 10,000 examples ဆိုပြီး ခွဲထားပါတယ်။ images နဲ့ labels ဆိုပြီး data နှစ်မျိုး ရှိပါတယ်။ images ထဲမှာတော့ digits တွေကို လက်ရေးမူအမျိုးမျိုးနဲ့ ရေးထားတဲ့ 28x28 pixels grayscale ပုံတွေပါပါတယ်။ labels မှာတော့ images ထဲက ပုံတစ်ပုံချင်းဆီရဲ့ class (0 to 9) ခွဲထားတာတွေ ပါပါတယ်။
ဒီ Link ကနေ
- Training dataset images: train-images-idx3-ubyte.gz (9.9 MB, 47 MB unzipped, and 60,000 examples)
- Training dataset labels: train-labels-idx1-ubyte.gz (29 KB, 60 KB unzipped, and 60,000 labels)
- Test dataset images: t10k-images-idx3-ubyte.gz (1.6 MB, 7.8 MB unzipped, and 10,000 examples)
- Test dataset labels: t10k-labels-idx1-ubyte.gz (5 KB, 10 KB unzipped, and 10,000 labels)
gzip file ၄ ခု down ထားရပါမယ်။ Windows User တွေကတော့ ကိုယ်ကြိုက်တဲ့ unzipping tool သုံးပြီး unzip လုပ်လို့ရပါတယ်။ Unix/Linux User တွေကိုတော့ gzip tool ကိုသုံးပြီး unzip လုပ်ဖို့ recommend ပေးပါတယ်။ local MNIST download directory ကနေ gzip *ubyte.gz -d ကို terminal က run ပေးရုံပါပဲ။
Unzip လုပ်ပြီးသွားရင်တော့ byte format ဖြစ်တဲ့ train-images.idx3-ubyte, train-labels.idx1-ubyte, t10k-images.idx3-ubyte, t10k-labels.idx1-ubyte ၄ခုစလုံးကို implementation မှာထည့်သုံးမယ့် numpy array အဖြစ်ပြောင်းရပါမယ်။ အဲ့အတွက် function တစ်ခု စရေးကြပါမယ်။
Step2 — Dataset Loading

load_mnist က unzip လုပ်ထားတဲ့ file path နဲ့ train or t10k ရွေးရမယ့် flag ကို input အနေနဲ့ယူပါတယ်။ ပထမ return တဲ့ array ကတော့ images (nxm dimensional numpy array) ပါ။ n ကတော့ number of examples ဖြစ်ပြီး m ကတော့ number of features (pixels) ပါ။ m နေရာမှာ images 28x28 pixels ကို unroll လုပ်ပြီ: (784 per row or images) ပါတဲ့ one dimensional row vector အနေနဲ့ပြောင်းပေးရမှာပါ။ (example: images for training data = 60,000x784 dimension, images for test data = 10,000x784 dimension) ဒုတိယ array မှာတော့ example တစ်ခုစီတိုင်းရဲ့ class label (integer 0–9) ပါပါတယ်။ example: [5 0 4 … 5 6 8]
magic, n = struct.unpack(‘>II’,lbpath.read(8))ကိုနားလည်အောင် အရင်ဆုံး MNIST website ကိုပြန်သွားပြီး description ကိုကြည့်ပါမယ်။
struct.unpack(format,buffer) ကတော့ byte data ကို format အတိုင်း unpack ပေးတာပါ။ format က ‘>II’ ဖြစ်တဲ့အတွက် > = big-endian, I = unsigned integer (4 bytes) ။ ဒီမှာတော့ lbpath.read(8)) buffer size က 8 bytes ဖြစ်တဲ့အတွက် big-endian unsigned integer 8 bytes format အနေနဲ့ဖတ်ပြီး unpack ရမယ်လို့ဆိုလိုပါတယ်။
images = ((images / 255.) — .5) * 2 ကတော့ pixel normalization လုပ်တာပါ။ range 0 ကနေ 255 ဖြစ်နေတဲ့ pixel values တွေကို range -1 ကနေ 1 အတွင်းရောက်အောင်ညှိလိုက်တာပါ။ 0–255 ဒီတိုင်း input အနေနဲ့ထည့်လိုက်လို့ရပေမယ့် integer value ကြီးတဲ့ အခါ Learining လုပ်တဲ့ Process ကိုနှေးကွေးစေလို့ပါ။ နောက်ဆုံးမှာတော့ Byte format data တွေအကုန်လုံးကို numpy array ပြောင်းပြီးသွားပါပြီ။

Step3 — Data Visualization
MNIST ထဲက handwritten digits ပုံတွေက ဘယ်လိုမျိုးတွေလဲဆိုတာ သိချင်ကြမယ်ထင်ပါတယ်။ 0 ကနေ 9 ထိ တစ်ပုံစီထုတ်ကြည့်ကြရအောင်။

နံပတ် 9 တစ်ခုတည်းကို လက်ရေးတွေဘယ်လိုကွဲပြားလဲမြင်ချင်ရင်တော့ အောက်က function လေးကို run ကြည့်လိုက်ပါ။ တခြား နံပတ်တွေအတွက်ကြည့်ချင်ရင်လည်း y_train == 9 နေရာမှာ အစားထိုးထည့်ကြည့်လို့ရပါတယ်။

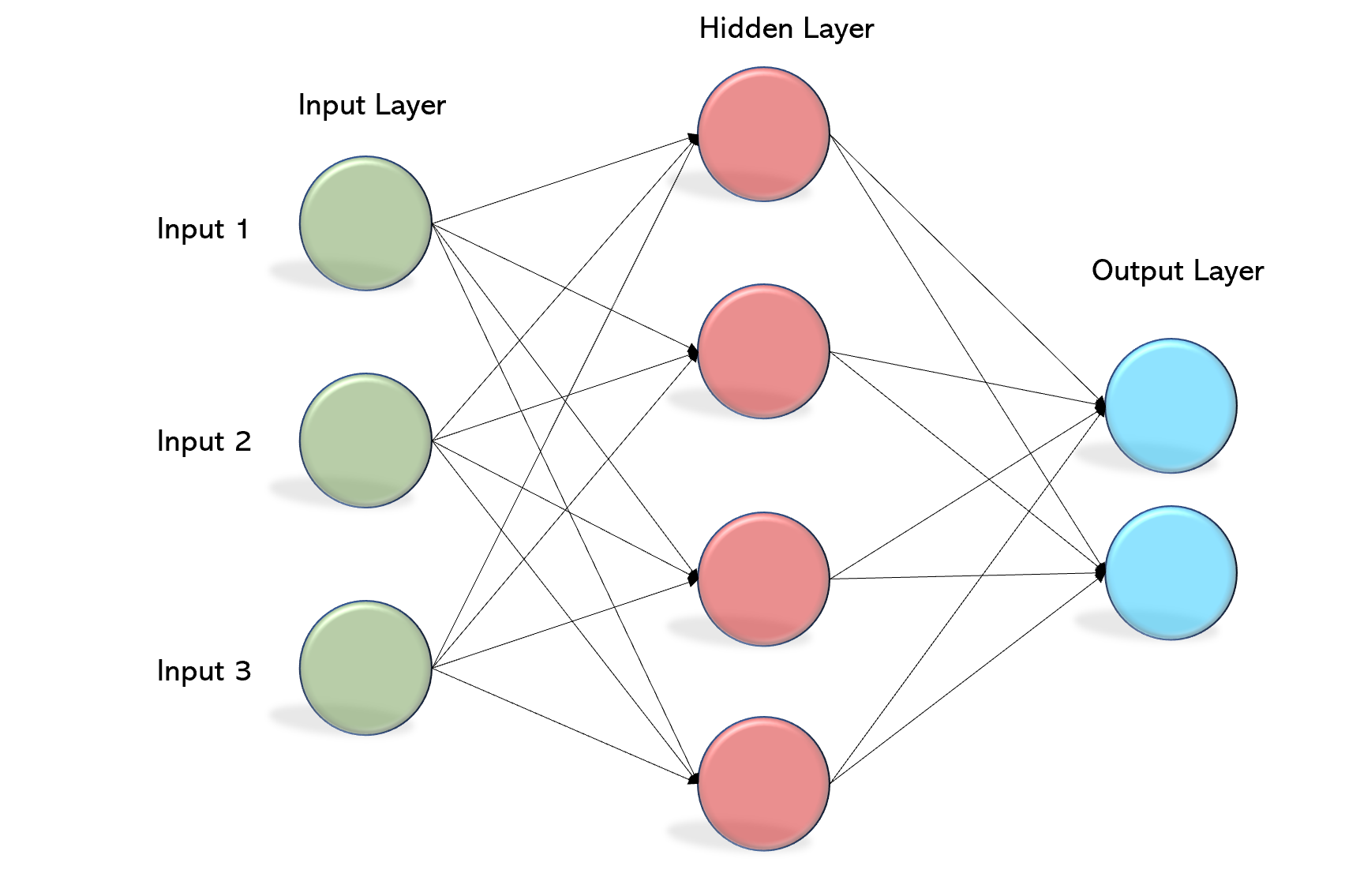
Step4 — Multilayer Perceptron Implementation

အလွယ်ကူဆုံး နဲ့ အရိုးရှင်းဆုံး one hidden layer MLP ကိုဆောက်ကြပါမယ်။

hidden unit, L2 regularization, learning rate စတဲ့ parameter တွေကို initialize လုပ်ပါမယ်။

one-hot representation ကတော့ label တွေကို Binary vector အဖြစ်ပြောင်းပေးပါတယ်။

Activation function ဖြစ်တဲ့ sigmoid function ကို implement လုပ်ပါမယ်။ Input တွေကို range က 0–1 အတွင်းဖြစ်အောင်ပြောင်းပေးနိုင်တာမို့ digit classification မှာ probability value တွေနဲ့အလုပ်လုပ်ရတဲ့အခါမှာ သင့်တော်ပါတယ်။

forward propagation မှာတော့ hidden layer, activation layer of hidden layer, input of output layer, activation layer of output layer ဆိုပြီး တစ်ဆင့်ချင်း implement လုပ်ထားပါတယ်။

cost function ကတော့ model ရဲ့ prediction ဘယ်လောက်မှန်လဲဆိုတာကိုပြပေးပါတယ်။ L2 regularization ဆိုတာကတော့ weight decay ဆိုတဲ့အတိုင်း weight တွေကို zero နားကပ်တဲ့အထိ လျော့ချဖို့အတွက် cost function မှာ hyperparameter တစ်ခုထပ်ပေါင်းထည့်တာဖြစ်ပါတယ်။ cost function တွက်တဲ့ နေရာမှာ L2 regularization ပါသုံးထားတဲ့အတွက် overfitting မဖြစ်ဖို့ပါ ထိန်းညှိပြီးသားဖြစ်ပါတယ်။

class label တွေ predict လုပ်ပါတဲ့ function ပါ။ neural network ကတွက်ထုတ်ပေးလိုက်တဲ့ probability value အများကြီးထဲကမှ အမြင့်ဆုံး value ရှိတဲ့ class ကိုရွေးချယ်တာပါ။ အနီးစပ်ဆုံး class ကို predict လုပ်ပေးတယ်လို့ပြောလို့ရပါတယ်။

လိုအပ်တဲ့ function တွေအကုန်ရေးပြီးတဲ့နောက်မှာ neural network ကို learning စလုပ်ခိုင်းဖို့အတွက် fit ဆိုတဲ့ function ကို ရေးပါမယ်။ Backpropagation ကတော့ အရင် Layer ရဲ့ error rate အပေါ်မူတည်ပြီး weight တွေကို fine-tuning လုပ်ပေးခြင်းဖြင့် prediction ရဲ့ accuracy ကိုပိုကောင်းအောင်လုပ်ပေးတဲ့ learning algorithm တစ်ခုပဲဖြစ်ပါတယ်။ backpropagation ဆိုတဲ့နာမည်အတိုင်း weight တွေကို output ကနေ input ဘက်ကိုပြန် update ပေးပါတယ်။
တစ်ခုချင်းခွဲပြီးရှင်းပြထားတဲ့အတွက် function လို့ခေါ်လိုက်ပေမယ့် အမှန်တစ်ကယ်က NeuralNetMLP ဆိုတဲ့ class ထဲက method တွေပါ။
Training Multilayer Neural Network
nn = NeuralNetMLP(n_hidden=100,l2=0.01,epochs=200, eta=0.0005, minibatch_size=100, shuffle=True, seed=1)Neural network ကို 784–100–10 MLP အဖြစ် initialize လုပ်ပါမယ်။ 784 input units (n_features), 100 hidden units (n_hidden), 10 output units (n_output):
- l2 : L2 regularization to decrease the degree of overfitting.
- epochs: number of passes over the training dataset.
- eta: learning rate.
- shuffle: shuffling the training set prior to every epoch to prevent the algorithm getting stuck in circles.
- seed: a random seed for shuffling and weight initialization.
- minibatch_size: number of training examples in each minibatch when splitting the training data in each epoch for SGD. The gradient is computed for each mini-batch separately instead of the entire training data for faster learning.
nn.fit(X_train=X_train[:55000], y_train=y_train[:55000], X_valid=X_train[55000:], y_valid=y_train[55000:])#result >> 200/200 | Cost: 5065.78 | Train/Valid Acc.: 99.28%/97.98%
shuffle လုပ်ထားပြီးသား MNIST training dataset ထဲမှ 55000 examples နဲ့ ကျန်တဲ့ 5000 examples ကိုတော့ validation အတွက်ထားပြီး model ကို train လုပ်ပါမယ်။ NN Training မှာတော့ training နဲ့ validation accuracy ကို compare လုပ်ကြည့်ပြီး model ရဲ့ performance ကောင်းမကောင်းကိုဆုံးဖြတ်ပါတယ်။ တစ်ကယ်လို့ training နဲ့ validation accuracy ကနည်းနေမယ်ဆိုရင် training dataset ဒါမှမဟုတ် hyperparameter တစ်ခုခုကအဆင်မပြေဖြစ်နေလို့ပါ။ training နဲ့ validation accuracy values အရမ်းကွာနေရင်လည်း overfitting ဖြစ်နေတတ်ပါတယ်။ training နဲ့ validation accuracy ကမြင့်နေမယ်ဆိုရင်တော့ model က မမြင်နိုင်တဲ့ data အသစ်တွေအတွက်ပါ ကောင်းကောင်း အလုပ်လုပ်နိုင်တယ်လို့ ပြောနိုင်ပါတယ်။
Step5 — Metrics Visualization
eval_ attribute ထဲက epoch တစ်ခုစီအတွက်သိမ်းထားတဲ့ cost, training, validation accuracy တွေကို visualize လုပ်ကြည့်ပါမယ်။ cost ကိုအရင် ထုတ်ကြည့်ပါမယ်။

ပထမ 100 epochs မှာတော့ cost ကဖြည်းဖြည်းချင်း လျော့လာပေမယ့် နောက် 100 epochs ကနေစပြီး cost ကဖြည်းဖြည်းချင်း zero နားကို converge ဖြစ်လာပါတယ်။
training accuracy နဲ့ validation accuracy ကို plot ချကြည့်ပါမယ်။

plot ကနေမှ training နဲ့ validation accuracy ရဲ့ကွာခြားချက်က epochs များများ train လေ ပိုများလာလေဆိုတာကို တွေ့ရမှာပါ။ epochs 50 နားလောက်မှာ တန်ဖိုးတူသွားပေမယ့် အဲ့ဒီနောက်ပိုင်းကစပြီး overfitting စဖြစ်လာပါတယ်။ overfitting ကိုလျော့ချဖို့အတွက် regularization ကိုတိုးပေးရပါမယ်။(example: l2 = 0.1)
test dataset ပေါ်မှာ predict လုပ်ထားတဲ့ prediction accuracy ကိုထုတ်ပါမယ်။

Training data ပေါ်မှာ နည်းနည်း overfit ဖြစ်နေတာကလွဲလို့ model ရဲ့ performance က test data ပေါ်မှာတော့ ကောင်းကောင်းအလုပ်လုပ်ပါတယ်။
prediction မှန်တဲ့ ပုံတွေကို အရင်ထုတ်ကြည့်ပါမယ်။
t : true class label
p: predicted class label

prediction မမှန်တဲ့ ပုံတွေ ထုတ်ကြည့်ပါမယ်။ တစ်ချို့ပုံတွေကတော့ လူတောင်မျက်စိမှားနိုင်တဲ့အတွက် model အတွက်လည်း မှန်အောင် predict လုပ်ဖိုခက်ပါတယ်။

🔰အချိန်ပေးပြီး ဖတ်ပေးကြတဲ့အတွက် အားလုံးကိုကျေးဇူးတင်ပါတယ်🔰
References
1) python machine learning 3rd edition — chapter 12: Implementing a Multilayer Artificial Neural Network from Scratch

{kind=link}